들어가며
새삼스래 왠 재입문? JavaScript가 the world's most misunderstood programming language (세계에서 가장 잘못 이해되고있는 프로그래밍 언어)에 소개된 것과 같이 의미있는 비판을 받고 있기 때문입니다. 장난감 정도로 비웃음을 사고 있지만, 그 속기쉬운 이면에는 몇가지 강력한 언어 요소를 내재하고 있습니다. 2005년에는 이 기술에 대한 깊은 이해가 웹 개발자 누구에게 있어서도 중요한 능력이 된다는 것을 보여주는 많은 고급 JavaScript 응용 프로그램들이 나타났습니다.
언어의 역사에서 시작하는 것이 이 이야기를 이해하는데 도움이 됩니다. JavaScript는 1995년 Netscape의 엔지니어 Brendan Eich에 의해 만들어졌고, 이른 1996년에 Netscape 2와 함께 처음 릴리즈 된것입니다. 원래 LiveScript로 불리워지기로 되어있었지만, Sun Microsystem의 Java 언어의 성공에 편승해보려고 두 언어 사이의 공통점이 매우 적음에도 불구하고, 이런 불행이 예견된 마케팅 결정에 따라 이름이 바뀌게 됩니다. 이 사실은 사상 유래가 없는 혼란의 근원이 되어버립니다.
Microsoft는 몇달 후 IE3와 함께 JavaScript와 대부분이 호환되는 JScript로 불리워지는 언어를 발표합니다. Netscape는 1997년에 ECMAScript 표준의 첫번째 판이 되는 JavaScript를 유럽 표준화 단체인 Ecma International에 보냅니다. 표준은 1999년에 ECMAScript edition 3에 따라 큰 규모의 개정을 거친 후, 현재 4번째 판이 제정 준비 중에 있지만 유래없이 아주 안정된 상태로 계속 유지되고 있습니다.
이 안정 상태는 다양한 코드 구현을 하는데 충분한 시간이기 때문에 개발자들에게는 더없이 좋은 소식입니다. 저는 대부분 이 3판에 집중하려고 합니다. 친숙함을 위하여 JavaScript 전반에 걸쳐 여기서 사용된 용어를 준수하겠습니다.
대부분의 프로그래밍 언어와는 달리, JavaScript 언어는 입출력 개념이 없습니다. 호스트 환경 아래에서 스크립트 언어로서 동작하도록 디자인 되어있고, 따라서 외부 세계와 통신하기위해 호스트 환경이 제공하는 메커니즘에 의존합니다. 대부분의 경우 일반적인 호스트 환경은 브라우저이지만 JavaScript 인터프리터는 Adobe Acrobat, Photoshop, Yahoo! 위젯 엔진, 등의 제품에서도 발견할 수 있습니다.
개요
어떤 언어에서라도 기초가 되는 부분인 타입을 살펴보는 것부터 시작해봅시다. JavaScript 프로그램은 값을 다루고 해당 값은 모두 타입을 가지고 있습니다. JavaScript의 타입은 다음과 같습니다:
... 오, 그리고 약간 특별한 타입인 정의되지않음(Undefined) 와 널(Null) 이 있습니다. 또한 객체의 특별한 종류인 배열(Array) 객체. 그리고 자유롭게 사용할 수 있는 날짜(Date) 객체 와 정규식(RegExp) 객체가 있습니다. 그리고 기술적으로 정확히 말해 함수(Function)는 단지 객체의 특별한 타입으로 취급됩니다. 따라서 타입 구조도를 정리해보면 다음과 같이 됩니다:
- 수 (Number)
- 문자열 (String)
- 부울 (Boolean)
- 객체 (Object)
- 함수 (Function)
- 배열 (Array)
- 날짜 (Date)
- 정규식 (RegExp)
- 널 (Null)
- 정의되지않음 (Undefined)
그리고 또 몇 가지 오류 타입이 내장되어 있습니다. 그렇지만 처음 구조도를 기억하고만 있으면 다른 것들도 아주 쉽게 이해할 수 있을 것입니다.
수 (Numbers)
설계 명세서에 의하면 JavaScript에서 수는 "이중정밀도 64비트 형식 IEEE 754 값"으로 정의됩니다. 이것은 몇가지 흥미로운 결과를 가져옵니다. JavaScript에는 정수와 같은 것이 존재하지 않으므로, C 나 Java 에서 수학 계산을 한 경험이 있다면 산술할 때 약간 조심할 필요가 있습니다. 다음과 같은 경우를 주의해야 합니다:
0.1 + 0.2 = 0.30000000000000004
덧셈, 뺄셈, 계수 (또는 나머지) 연산을 포함하는 표준 산술 연산자가 지원됩니다. 또한 앞에서 언급하는 것을 깜박 잊은 고급 수학 함수와 상수를 다루기 위한 수학(Math)으로 불리워지는 내장 객체가 있습니다:
Math.sin(3.5);
d = Math.PI * r * r;
내장 parseInt() 함수를 사용하여 문자열을 정수로 변환할 수 있습니다. 이는 다음과 같이 옵션으로 주어지는 두번째 매개변수를 밑으로 하여 수행할 수 있습니다:
> parseInt("123", 10)
123
> parseInt("010", 10)
10
밑을 주지 않으면, 다음과 같이 예상치 못한 결과를 얻을 수 있습니다:
> parseInt("010")
8
이 같은 결과는 parseInt 함수가 0으로 시작되는 문자열을 8진수로 취급하기 때문에 발생합니다.
만약 이진수를 정수로 변환하고 싶다면, 밑을 바꾸기만하면 됩니다:
> parseInt("11", 2)
3
문자열이 수가 아닌 경우 NaN ("Not a Number" (수가 아님)을 줄인 약자)로 불리워지는 특별한 값을 돌려줍니다:
> parseInt("hello", 10)
NaN
NaN 는 독성을 가지고 있습니다: 어떤 수학 연산의 입력값으로써 주어지면 그 결과는 역시 NaN가 되기 때문입니다:
> NaN + 5
NaN
내장 isNaN() 함수를 사용해서 NaN 인지 여부를 검사할 수 있습니다:
> isNaN(NaN)
true
JavaScript는 또 특별한 값 Infinity와 -Infinity를 가지고 있습니다:
> 1 / 0
Infinity
> -1 / 0
-Infinity
문자열 (Strings)
JavaScript에서 문자열은 문자 하나하나가 연결되어 만들어진 것입니다. 좀 더 정확히 말하자면, 각각이 16비트로 표현된 유니코드 문자들이 길게 이어져있는 것입니다. 이는 국제화(i18n, internationalization) 하려하는 누구에게라도 환영받을만한 소식입니다.
한 개의 문자를 나타내려면 길이가 1인 문자열을 사용하면 됩니다.
문자열의 길이를 알고싶다면, 해당 문자열의 length 속성(해당 객체가 소유하고 있는 성질을 나타내는 값)에 접근하면 됩니다:
> "hello".length
5
우리의 첫 JavaScript 객체입니다! 문자열도 역시 객체로 취급된다고 언급했던적이 있죠? 다음과 같이 메소드까지 있는 확실한 녀석입니다:
> "hello".charAt(0)
h
> "hello, world".replace("hello", "goodbye")
goodbye, world
> "hello".toUpperCase()
HELLO
이외의 타입들
JavaScript는 의도적으로 값이 없음을 가리키는 '객체' 타입의 객체인 null과 초기화되지 않은 값 — 아직 어떤 값도 주어지않은(할당되지않은) 변수임을 가리키는 '정의되지 않음' 타입의 객체인 undefined로 구분됩니다. 값에 대해서 나중에 언급할 것이지만 JavaScript에서 변수에 값을 주지않고 선언하는 것이 가능합니다. 이럴 경우, 변수의 타입은 undefined이 되는 것입니다.
JavaScript는 true 와 false 값 (둘은 모두 키워드로 예약되어있는 값)을 가질 수 있는 부울 타입을 가지고 있습니다. 다음과 같은 규칙에 따라 어떤 임의의 값을 부울값으로 변환할 수 있습니다:
false, 0, 빈 문자열 (""), 수가 아님을 뜻하는 NaN, null, 와 undefined은 모두 false가 됩니다.- 다른 모든 값은
true가 됩니다.
이 변환은 Boolean() 함수를 써서 명시적으로 이 작업을 수행하실 수 있습니다:
> Boolean("")
false
> Boolean(234)
true
하지만 반드시 이렇게 할 필요는 거의 없습니다. JavaScript는 이러한 변환 작업을 if 문 (아래를 보세요)과 같이 부울값이 필요한 경우를 만나게되면 자동으로 사용자가 모르는 사이에 처리해버리기 때문입니다. 이러한 이유로 인해 우리는 가끔 부울 타입으로 변환되었을 때, true와 false이 됨을 의미하는 값들을 각각 "참 값"과 "거짓 값"으로 부를 것입니다. 또는 각각 "참으로 취급되다"와 "거짓으로 취급되다"라는 식으로 불릴 수도 있습니다.
부울 연산자는 && (논리적 와, 그리고), || (논리적 또는), 그리고 ! (논리적 부정)이 지원됩니다. 아래에서 다시 언급하겠습니다.
변수 (Variables)
JavaScript에서 새로운 변수는 var 키워드로 선언됩니다:
var a;
var name = "simon";
만약 변수에 아무런 값을 주지 않고 선언하면 해당 변수의 타입은 undefined가 됩니다.
JavaScript에는 블록 유효 범위가 따로 없습니다. 여기에 대한 것은 블록 문장에서 참고바랍니다.
연산자 (Operators)
JavaScript의 산술 연산자로는 +, -, *, /, %(나머지 연산자)가 있습니다. 값은 = 연산자로 할당할 수 있고, += 와 -=처럼 다른 연산자를 같이사용해서 할당할 수 있습니다. 이렇게 쓰인 연산자는 x = x 연산자 y와 같은 결과를 나타냅니다.
x += 5
x = x + 5
++ 와 -- 를 각각 점진적인 증가와 감소에 사용할 수 있습니다. 이들은 또한 전처리 또는 후처리 연산자로 사용될 수 있습니다.
+ 연산자는 문자열 이어붙이기도 합니다:
> "hello" + " world"
hello world
문자열에 어떤 수 (또는 다른 값)를 더하면 일단 모두 문자열로 바뀌게 됩니다. 다음 예를 보시면 무슨 말씀인지 아실 수 있을겁니다:
> "3" + 4 + 5
345
> 3 + 4 + "5"
75
빈 문자열에 어떤 값을 더하는 것은 해당 값을 문자열로 바꾸는 요령입니다.
JavaScript에서 비교는 <, >, <= 와 >= 를 통해 가능합니다. 이 연산자들은 문자열과 수 양쪽 모두에서 동작합니다. 상동은 약간 직관성이 떨어지는데 이중 등호 (==) 연산자는 서로 다른 타입을 줄 경우 타입 강제 변환을 수행하기 때문에 다음과 같이 때때로 기대하지 않은 결과를 내보내기 때문입니다:
> "dog" == "dog"
true
> 1 == true
true
타입 강제 변환을 하지 않게 하려면, 삼중 등호 연산자 (===)를 사용해야합니다:
> 1 === true
false
> true === true
true
이와 비슷하게 != 와 !== 연산자가 있습니다.
JavaScript는 값을 비트로 취급하는 연산자도 가지고 있습니다. 사용하고 싶을 때 언제라도 사용할 수 있도록 말이죠.
제어 구조
JavaScript는 C 계열의 다른 언어들과 비슷한 제어 구조를 가지고 있습니다. 조건문은 if 와 else를 지원하는데, 원하시는대로 얼마든지 중첩 시켜서 사용할 수 있습니다:
var name = "kittens";
if (name == "puppies") {
name += "!";
} else if (name == "kittens") {
name += "!!";
} else {
name = "!" + name;
}
name == "kittens!!"
JavaScript는 while 반복문과 do-while 반복문도 사용할 수 있습니다. 첫번째 것은 단순 반복에 유용하게 사용할 수 있고, 두번째 것은 반복문이 반드시 적어도 한번이상 실행 되도록 하고 싶을 때 사용할 수 있습니다:
while (true) {
// an infinite loop!
}
do {
var input = get_input();
} while (inputIsNotValid(input))
JavaScript의 for 반복문은 C 와 Java의 그것과 같습니다. 말하자면, 반복문에 필요한 제어 정보를 한줄에 표현할 수 있다는 이야기지요.
for (var i = 0; i < 5; i++) {
// Will execute 5 times
}
&& 와 || 연산자는 첫번째 식을 평가한 결과에 따라서 두번째 식을 평가를 실행하는 단축평가(short-circuit) 논리를 사용합니다. 이는 다음과 같이 객체에 접근하기 전에 null 객체인지, 아닌지를 검사하는데 유용하게 사용될 수 있습니다:
var name = o && o.getName();
또는 기본 값 설정을 위해서 다음과 같이 이 성질을 사용할 수 있습니다:
var name = otherName || "default";
JavaScript는 한줄로 조건문을 쓸 수 있게 해주는 삼중 연산자도 가지고 있습니다:
var allowed = (age > 18) ? "yes" : "no";
스위치 문은 숫자나 문자열을 기반으로 다중 분기되는 문장을 작성하는데 사용될 수 있습니다:
switch(action) {
case 'draw':
drawit();
break;
case 'eat':
eatit();
break;
default:
donothing();
}
break 문장을 추가하지 않았다면, 다음 단계로 "넘어가서" 실행합니다. 이렇게 되는 것을 기대하는 것은 매우 드문경우 입니다. 실은 디버깅하는데 용이하도록 하기위해 주석으로서 일부러 붙여놓은 넘어가기 이름표 입니다:
switch(a) {
case 1: // fallthrough
case 2:
eatit();
break;
default:
donothing();
}
default 구문은 선택적으로 적용할 수 있습니다. 스위치와 케이스 부분에서 원할경우 둘다 식을 사용할 수 있습니다. === 연산자를 사용해서 두 문장을 비교해보시기 바랍니다.
switch(1 + 3):
case 2 + 2:
yay();
break;
default:
neverhappens();
}
객체 (Objects)
JavaScript 객체는 간단히 이름-값 쌍(name-value pairs)의 모임입니다. 그렇기 때문에, JavaScript의 객체의 모임은 다음과 비슷하다고 할 수 있습니다:
- Python의 Dictionaries
- Perl 과 Ruby의 Hashes
- C 와 C++ 의 Hash tables
- Java 의 HashMaps
- PHP의 Associative arrays
이 데이터 구조가 매우 광범위하게 사용된다는 사실은 활용 방도가 다양함을 입증합니다. JavaScript내 모든 것 (코어 타입들은 제외)은 객체로 취급되기 때문에 어떤 JavaScript 프로그램도 기본적으로 해쉬 테이블을 검색하는데 필요한 출중한 성능을 가지고 있습니다. 매우 빠르기 때문에 장점이 됩니다!
값은 객체를 포함하여 아무 JavaScript 값이 될 수 있는 반면, "이름" 부분은 JavaScript 문자열 입니다. 이는 무작위적인 복잡성을 가지는 데이터 구조를 만들 수 있도록 해줍니다.
빈 객체를 생성하는데 두가지 방법이 있습니다:
var obj = new Object();
와:
var obj = {};
이들은 의미적으로 동치입니다. 두번째 방법은 객체의 엄밀한 구문으로 말할 수 있으며 더 편리합니다. 객체 엄밀 구문이 초기 버전에는 없었기 때문에 예전 방법을 사용한 코드를 많이 볼 수 있습니다.
일단 생성되면, 객체의 속성에 다음의 두가지 방법들 중 한가지로 접근할 수 있습니다:
obj.name = "Simon"
var name = obj.name;
그리고...
obj["name"] = "Simon";
var name = obj["name"];
이들은 의미적으로 역시 같습니다. 두번째 방법은 속성의 이름이 실행시간(run-time)에 계산될 수 있는 문자열로 주어집니다. 또한 예약된 단어(키워드)로 되어있는 이름으로 객체의 속성을 설정하거나 얻어낼 수 있습니다:
obj.for = "Simon"; // 구문 오류, for 가 예약된 단어(키워드)이기 때문에
obj["for"] = "Simon"; // 정상 동작
객체 엄밀 구문으로 객체의 전체적인 구조를 초기화 할 수 있습니다:
var obj = {
name: "Carrot",
"for": "Max",
details: {
color: "orange",
size: 12
}
}
속성에 연속적으로 접근할 수 있습니다:
> obj.details.color
orange
> obj["details"]["size"]
12
배열 (Arrays)
JavaScript에서 배열은 실제로는 객체의 특별한 타입입니다. (숫자로 나타낸 속성은 자연스럽게 [] 구문만을 사용해서 접근하게 되므로) 일반 객체와 많이 비슷하게 동작하지만, 이 객체는 'length'라는 한가지 마법 속성을 가집니다. 이는 항상 배열에서 가장 큰 인덱스보다 하나 더 큰 값으로 존재합니다.
배열을 생성하는 예전 방법은 다음과 같습니다:
> var a = new Array();
> a[0] = "dog";
> a[1] = "cat";
> a[2] = "hen";
> a.length
3
한가지 더 편리한 배열 표현 방법은 배열 상수를 사용하는 것입니다:
> var a = ["dog", "cat", "hen"];
> a.length
3
배열 상수 끝에 콤마(",")를 꼬리로 남겨두는 것은 브라우저마다 다르게 처리하므로 그렇게 하지는 마시기 바랍니다.
array.length 는 배열에 들어있는 항목의 수를 반드시 반영하지는 않는다는 점을 주의하시기 바랍니다. 다음과 같은 경우를 고려해보겠습니다:
> var a = ["dog", "cat", "hen"];
> a[100] = "fox";
> a.length
101
기억해두세요 - 배열의 length 속성은 최대 인덱스에 하나를 더한 값일 뿐입니다.
존재하지 않는 배열 인덱스를 참조하려고하면 다음과 같이 undefined 을 얻게됩니다:
> typeof(a[90])
undefined
위의 사항들을 감안하면 배열을 반복문으로 처리할 때 다음과 같은 방법으로 처리하실 수 있을 것입니다:
for (var i = 0; i < a.length; i++) {
// a[i] 로 뭔가를 수행
}
이 코드는 루프를 반복할 때마다 배열의 length 속성을 찾아보게되므로 약간 비 효율적입니다. 개선책은:
for (var i = 0, len = a.length; i < len; i++) {
// a[i] 로 뭔가를 수행
}
보다 더 좋은 관용적인 코드는:
for (var i = 0, item; item = a[i]; i++) {
// item 으로 뭔가를 수행
}
여기서 우리는 두개의 변수를 설정합니다. for 루프 중간 부분의 할당문은 참인지 거짓인지 테스트 하는데, 참으로 밝혀지면, 루프를 계속 돕니다. i가 루프를 돌 때마다 하나씩 증가하기 때문에 배열의 항목들은 순차적으로 item 변수에 할당됩니다. "거짓으로 취급되는" 항목 (undefined와 같은 항목)을 발견하면 루프는 멈춥니다.
이 요령은 "거짓으로 취급되는" 값이 포함되지 않은, 예를 들어 객체의 배열이나 DOM 노드들과 같은 배열에 사용되어야만 합니다. 0을 포함하는 수로 표현된 데이터나 빈 문자열을 포함하는 문자열 데이터에 대하여 반복문을 적용할 경우에는 i, j를 사용하는 관용 코드를 대신 사용해야 합니다.
반복문을 사용하는 또다른 방법은 for...in 루프를 사용하는 것입니다. 누군가가 Array.prototype에 새로운 속성을 추가한 경우, 이 루프에 의해 그 속성도 반복된다는 점을 주의하시기 바랍니다:
for (var i in a) {
// a[i] 으로 뭔가를 수행
}
배열에 어떤 항목을 덧붙이길 원하면 다음과 같이 안전한 방법으로 수행할 수 있는 방법이 있습니다:
a[a.length] = item; // a.push(item); 와 같음
a.length는 가장 큰 인덱스의 하나더 큰 값이기 때문에 배열 끝의 빈 공간에 할당한다는 점을 확신할 수 있습니다.
배열 객체은 다음과 같이 많은 메소드를 사용할 수 있습니다:
a.toString(), a.toLocaleString(), a.concat(item, ..), a.join(sep),
a.pop(), a.push(item, ..), a.reverse(), a.shift(), a.slice(start, end),
a.sort(cmpfn), a.splice(start, delcount, [item]..), a.unshift([item]..)
concat 해당 배열에 지정한 항목들을 추가한 새로운 배열을 돌려줍니다pop 마지막 항목을 제거한 다음 돌려둡니다push 마지막에 하나 이상의 항목을 추가합니다 (ar[ar.length]와 같이)slice 배열의 일부분을 돌려줍니다sort 비교에 사용할 함수를 따로 지정할 수 있습니다splice 구역을 삭제하거나 항목을 추가해서 배열을 수정할 수 있게합니다unshift 배열의 시작부분에 항목을 붙일 수 있습니다
함수 (Functions)
객체와 마찬가지로, 함수는 JavaScript를 이해하는데 핵심이되는 컴포넌트입니다. 가장 기본적인 함수의 예는 다음과 같습니다:
function add(x, y) {
var total = x + y;
return total;
}
이 예는 기본 함수에 대해 알아야할 모든 것을 보여주고 있습니다. JavaScript 함수는 0 이상의 이름이 있는 매개변수를 가질 수 있습니다. 함수의 본체는 원하는 만큼의 문장을 포함할 수 있고 해당 함수에 지역적으로 변수를 보유하도록 선언할 수 있습니다. return 문은 언제나 값을 돌려주고 함수의 실행을 끝내는데 사용될 수 있습니다. 리턴 문이 없으면 (혹은 값이 없는 리턴이) 사용되면, JavaScript는 undefined을 돌려줍니다.
이름 붙여진 매개변수들은 다른 어떤 것보다도 해당 함수가 어떤 함수인지 설명해주는 좋은 역할을 할 수 있습니다. 해당 함수가 원하는 매개변수를 주지않고 함수를 호출할 수 있지만 그럴 경우 해당 변수들은 undefined로 설정됩니다.
> add()
NaN // undefined에 대해 덧셈을 수행할 수 없습니다
함수가 기대하는 원래의 매개변수보다 많은 배개변수를 넘겨줄 수도 있습니다:
> add(2, 3, 4)
5 // 처음의 두 수가 더해집니다. 4는 무시됨
이 예는 조금 바보같아보이지만, 함수는 추가적으로 주어진 변수는 해당 함수 내에서 매개변수로 넘겨진 모든 값을 가지고 있는 배열과 비슷한 객체인 arguments로 접근할 수 있습니다. 우리가 원하는만큼 값을 취하는 add 함수를 다시 써보겠습니다:
function add() {
var sum = 0;
for (var i = 0, j = arguments.length; i < j; i++) {
sum += arguments[i];
}
return sum;
}
> add(2, 3, 4, 5)
14
하지만 2 + 3 + 4 + 5을 직접쓰는 것보다 더 좋지는 않으니, 평균내는 함수를 만들어 보겠습니다:
function avg() {
var sum = 0;
for (var i = 0, j = arguments.length; i < j; i++) {
sum += arguments[i];
}
return sum / arguments.length;
}
> avg(2, 3, 4, 5)
3.5
이건 매우 유용합니다만 새로운 문제점도 함께 따라왔습니다. avg() 함수는 콤마로 구분된 매개변수 목록을 취하지만, 배열의 평균을 내고 싶은 경우라면요? 함수를 다음과 같이 다시 쓰기만 하면 됩니다:
function avgArray(arr) {
var sum = 0;
for (var i = 0, j = arr.length; i < j; i++) {
sum += arr[i];
}
return sum / arr.length;
}
> avgArray([2, 3, 4, 5])
3.5
하지만 우리가 이미 만든 함수를 다시 사용할 수 있다면 좋을 것입니다. 운이 좋게도 JavaScript는 함수 객체라면 모두 가지게 되는 apply() 메소드를 사용해서 임의의 매개변수 배열을 함수에 넘겨줄 수 있습니다.
> avg.apply(null, [2, 3, 4, 5])
3.5
두번째 매개변수 apply()는 배열을 매개변수로 사용합니다. 첫번째 매개변수는 나중에 설명하도록 하겠습니다. 이는 함수가 역시 객체임을 명확히 해주는 사실입니다.
JavaScript는 익명의 함수를 만들 수 있도록 허용하고 있습니다.
var avg = function() {
var sum = 0;
for (var i = 0, j = arguments.length; i < j; i++) {
sum += arguments[i];
}
return sum / arguments.length;
}
이것은 의미적으로 function avg() 형식과 같습니다. 문장의 어느 곳에나 일반적인 방식으로 완전한 함수 정의를 넣을 수 있도록 허용하는 것이기 때문에 매우 강력합니다. 이는 다양한 요령을 부릴 수 있게합니다. 다음 예는 C 의 블록 유효 범위를 적용 시킨 것 처럼 지역 변수를 "숨기는" 요령을 보여줍니다:
> var a = 1;
> var b = 2;
> (function() {
var b = 3;
a += b;
})();
> a
4
> b
2
JavaScript는 재귀적으로 함수를 부를 수 있습니다. 이는 브라우저 DOM 등에서 얻을 수 있는 트리 구조를 다루는데 유용합니다.
function countChars(elm) {
if (elm.nodeType == 3) { // TEXT_NODE
return elm.nodeValue.length;
}
var count = 0;
for (var i = 0, child; child = elm.childNodes[i]; i++) {
count += countChars(child);
}
return count;
}
다음의 예는 익명 함수를 사용함에 있어 잠재적인 문제점을 보여줍니다: 이름이 없으면 어떻게 재귀적으로 부를 수 있을까요? 답은 매개변수의 목록으로서의 역할을 수행함과 동시에 arguments.callee로 불리우는 속성을 제공하는 arguments 객체에 나와있습니다. 이는 현재의 함수를 반영하기 때문에 익명 함수도 재귀적으로 부를 수 있게 해줍니다:
var charsInBody = (function(elm) {
if (elm.nodeType == 3) { // TEXT_NODE
return elm.nodeValue.length;
}
var count = 0;
for (var i = 0, child; child = elm.childNodes[i]; i++) {
count += arguments.callee(child);
}
return count;
})(document.body);
arguments.callee는 현재 함수이고 모든 함수는 객체이므로, 같은 함수를 여러번 부르는 동안의 정보를 저장하는데 arguments.callee를 사용할 수 있습니다. 다음의 예는 함수 자체가 몇 번 불리워졌는지 기억하는 함수 입니다:
function counter() {
if (!arguments.callee.count) {
arguments.callee.count = 0;
}
return arguments.callee.count++;
}
> counter()
0
> counter()
1
> counter()
2
사용자 정의 객체
고전 객체지향 프로그래밍에서 객체는 데이터와 해당 데이터들을 다루는 메소드의 집합이었습니다. 이름과 성을 필드로 가지고 있는 'person' 객체를 고려해보도록 합시다. 이름을 표시하는 두가지 방법이 있을 수 있습니다. 예를 들어, "이름 성" 또는 "성, 이름" 이런 식으로 말이죠. 이전에 다룬 함수와 객체를 사용해서 이를 표현하면 다음과 같습니다:
function makePerson(first, last) {
return {
first: first,
last: last
}
}
function personFullName(person) {
return person.first + ' ' + person.last;
}
function personFullNameReversed(person) {
return person.last + ', ' + person.first
}
> s = makePerson("Simon", "Willison");
> personFullName(s)
Simon Willison
> personFullNameReversed(s)
Willison, Simon
이렇게하면 작동하긴하지만, 너무 어설픕니다. 전역 이름공간에 관련 함수가 주렁주렁 달려야 하니까요. 정말 우리에게 필요한 것은 객체에 함수를 붙여놓는 것입니다. 함수는 객체이기 때문이 이렇게 하는 것은 쉽습니다:
function makePerson(first, last) {
return {
first: first,
last: last,
fullName: function() {
return this.first + ' ' + this.last;
},
fullNameReversed: function() {
return this.last + ', ' + this.first;
}
}
}
> s = makePerson("Simon", "Willison")
> s.fullName()
Simon Willison
> s.fullNameReversed()
Willison, Simon
여기서 우리가 기존에 보지 못했던 뭔가를 볼 수 있습니다: 'this' 키워드가 바로 그것입니다. 함수 안쪽에서 사용되어, 'this'는 현재 객체를 참조합니다. 그것이 실재로 의미하는 바는 당신이 부른 바로 그 함수를 지정하는 것입니다. 객체에서 점 표기법이나 꺽쇠 괄호 표기법을 사용해서 부른 경우, 해당 객체는 'this'가 됩니다. 함수를 부르는데 점 기호를 사용하지 않은 경우, 'this'는 전역 객체를 참조합니다. 이 때문에 다음과 같은 실수가 자주 발생합니다:
> s = makePerson("Simon", "Willison")
> var fullName = s.fullName;
> fullName()
undefined undefined
fullName()을 불렀을 때, 'this'는 전역 객체에 속해있습니다. 불러낼 first 또는 last 전역 변수가 없기 때문에 각각에 대해 undefined 결과를 얻게됩니다.
makePerson 함수를 향상시키는데 'this' 코드의 잇점을 취할 수 있도록 해보겠습니다:
function Person(first, last) {
this.first = first;
this.last = last;
this.fullName = function() {
return this.first + ' ' + this.last;
}
this.fullNameReversed = function() {
return this.last + ', ' + this.first;
}
}
var s = new Person("Simon", "Willison");
여기서 'new'라는 또다른 키워드를 도입했습니다. new는 'this'와 깊게 연관되어 있습니다. 새로운 빈 객체를 만든 다음 지정된 함수를 불러 새로운 객체를 'this' 에 설정합니다. 'new' 에 의해 불리워지도록 디자인된 함수는 컨스트럭터 함수라고 불리워집니다. 보통 실재에서는 이러한 함수의 첫자를 대문자로 써서 new로 불리워질 컨스트럭터 함수임을 나타냅니다.
우리가 만들었던 person 객체가 점점 개선되고 있지만, 아직 좀 생뚱맞은 면이 있습니다. 매번 person 계열의 객체를 만들 때마다 그 안에 2개의 새로운 함수 객체를 만들어줘야 하는 걸까요? 이 코드를 공유하도록 해보면 어떨까요?
function personFullName() {
return this.first + ' ' + this.last;
}
function personFullNameReversed() {
return this.last + ', ' + this.first;
}
function Person(first, last) {
this.first = first;
this.last = last;
this.fullName = personFullName;
this.fullNameReversed = personFullNameReversed;
}
이렇게 메소드 함수를 한번 만들어서 컨스트럭터 내에 해당 메소드들을 참조하도록 할당하는게 하는게 더 낫습니다. 이보다 더 낫게 할 수 있을까요? 네, 그렇게 할 수 있습니다:
function Person(first, last) {
this.first = first;
this.last = last;
}
Person.prototype.fullName = function() {
return this.first + ' ' + this.last;
}
Person.prototype.fullNameReversed = function() {
return this.last + ', ' + this.first;
}
Person.prototype는 인스턴스된 모든 Person 객체에서 공유할 수 있는 객체입니다. 이는 찾아보기 체인의 한 부분을 이룹니다. (이건 "prototype chain"이라는 특수한 이름을 따로 가지고 있습니다) 다시 말해, Person 객체의 설정되지 않은 속성에 접근을 시도할 때마다 JavaScript는 Person.prototype에 대신 존재하는 속성이 있는지 없는지 살펴봅니다.
이것은 믿을 수 없을 정도로 강력한 도구입니다. JavaScript는 어떤 객체의 prototype을 프로그램 내에서 언제든지 변형할 수 있게합니다. 다시 말해, 다음과 같이 실행시간 언제든지 이미 존재하는 객체에 추가적인 메소드 추가가 가능하다는 이야기입니다:
> s = new Person("Simon", "Willison");
> s.firstNameCaps();
TypeError on line 1: s.firstNameCaps is not a function
> Person.prototype.firstNameCaps = function() {
return this.first.toUpperCase()
}
> s.firstNameCaps()
SIMON
흥미롭게도, 기본적으로 들어있는 JavaScript 객체 prototype에 더할 수 있습니다. String 객체에 문자열을 뒤집어서 돌려주는 메소드를 추가해보도록 합시다:
> var s = "Simon";
> s.reversed()
TypeError on line 1: s.reversed is not a function
> String.prototype.reversed = function() {
var r = "";
for (var i = this.length - 1; i >= 0; i--) {
r += this[i];
}
return r;
}
> s.reversed()
nomiS
우리가 추가한 새로운 메소드는 심지어 문자열 자체에서도 동작합니다!
> "This can now be reversed".reversed()
desrever eb won nac sihT
기존에 언급한 바와같이, prototype은 체인의 한 부분을 이룹니다. 해당 체인의 루트는 객체를 문자열로 나타내려할 때 부르게되는 toString() 메소드를 포함하는 Object.prototype 입니다. 이 메소드는 우리의 Person 객체의 디버깅에 유용하게 사용할 수 있습니다:
> var s = new Person("Simon", "Willison");
> s
[object Object]
> Person.prototype.toString = function() {
return '<Person: ' + this.fullName() + '>';
}
> s
<Person: Simon Willison>
avg.apply()의 첫번째 매개변수가 null 이었던걸 기억하십니까? apply()에 적용되는 첫번째 매개변수는 'this'로 취급될 수 있는 객체이어야만 합니다. 예를 들어, 'new'의 간단한 실례를 보도록 합시다:
function trivialNew(constructor) {
var o = {}; // 빈 객체를 생성
constructor.apply(o, arguments);
return o;
}
이것은 prototype 체인을 설정하지 않으므로 new의 완벽한 대체물이 될 수 없습니다. apply() 는 설명하기 어렵습니다. 자주 사용하지는 않아도 알아두면 좋겠지요.
apply() call 이름을 가진 자매 함수를 가지고 있습니다. 이는 역시 'this'를 다시 설정할 수 있게하지만, 동시에 apply()와는 대조적으로 확장된 메소드 리스트를 가지게됩니다.
function lastNameCaps() {
return this.last.toUpperCase();
}
var s = new Person("Simon", "Willison");
lastNameCaps.call(s);
// 위의 구문은 다음과 같습니다:
s.lastNameCaps = lastNameCaps;
s.lastNameCaps();
내장 함수
JavaScript 함수 선언은 내부에 다른 함수를 허용합니다. 우리는 이것은 예전에 makePerson() 함수 최초 버전에서 한번 본적이 있습니다. JavaScript 내장 함수의 세부사항 중에 중요한 것은 다음과 같이 그들이 속해있는 부모 함수 범위에 있는 변수에 접근할 수 있다는 사실입니다:
function betterExampleNeeded() {
var a = 1;
function oneMoreThanA() {
return a + 1;
}
return oneMoreThanA();
}
이 사실은 많이 사용하는 유틸리티를 쓸 때 좀 더 유지관리가 쉬운 코드를 작성할 수 있도록 해줍니다. 어떤 함수가 사용하는 다른 몇개의 함수가 작성한 코드의 다른 부분에는 별로 유용하지 않는 코드라면, 이런 유틸리티 함수를 해당 함수를 불러서 사용하는 함수의 내부에 내장되도록 할 수 있습니다. 전역 범위에 들어 있는 함수의 수를 낮게 유지합니다. (이렇게 하는 것은 항상 좋다고 볼 수 있습니다.)
이것은 또한 전역 변수에 대한 유혹을 뿌리칠 수 있는 좋은 대안이 됩니다. 복잡한 코드를 쓸 때, 보통 다양한 함수들간에 변수를 공유할 수 있도록 전역 변수 사용 유혹을 받기 쉽습니다 - 코드 유지 보수가 힘들죠. 내장 함수는 그 부모 함수의 변수를 공유할 수 있으므로, 이 방법을 사용하면 전역 변수 이름공간을 과도하게 사용하지 않고도 연관된 함수를 묶을 수 있습니다. - '지역 전역'이라고 불러도 괜찮겠네요. 이 기술을 사용할 때는 주의를 요하겠지만, 반드시 알아둬야할 유용한 기술입니다.
폐포 (Closures)
폐포 (글자 그대로 한국어로 해석하면 닫힌 주머니)는 JavaScript가 제공해야만 하는 가장 막강한 추상 계념으로 우리를 이끕니다 - 하지만 동시에 잠재적으로 가장 혼란스럽기도 합니다. 다음 함수는 무엇을 하는 걸까요?
function makeAdder(a) {
return function(b) {
return a + b;
}
}
x = makeAdder(5);
y = makeAdder(20);
x(6)
?
y(7)
?
makeAdder 함수의 이름은 다음과 같은 과정을 거쳐 반드시 없어집니다: 해당 함수가 한 매개변수를 받아 불리워졌을 때, 생성될 때 주어진 매개변수를 더하는 새 'adder' 함수를 생성합니다.
여기서 일어나는 일은 다른 함수의 내에 정의된 어떤 함수가 외부 함수의 변수에 액세스한다는 점에서 앞에 언급한 내장 함수에서 일어나는 일과 매우 비슷합니다. 한가지 다른 점은 외부 함수가 리턴 된다는 점인데, 상식적으로 그것에 들어 있는 변수는 사라진다고 볼 수 있습니다. 하지만 그들은 여전히 존재합니다 - 그렇지 않으면 adder 함수는 동작하지 않겠지요. 게다가, makeAdder 지역 변수의 서로 다른 두 "복사본"이 존재합니다 - 하나의 a는 5이고, 다른 하나의 a는 20이죠. 따라서 해당 함수를 부른 결과는 다음과 같습니다:
x(6) // 11을 돌려줌
y(7) // 27을 돌려줌
이건 실재로 일어나는 일입니다. JavaScript 함수가 실행될 때는 언제나, '범위' 객체가 생성되어 해당 함수내에서 생성된 지역 변수를 여기에 저장하고 있습니다. 함수 매개변수로서 넘겨진 어떤 변수라도 여기에 초기값으로 저장하고 있습니다. 이것은 모든 전역 변수와 함수가 들어있는 전역 객체와 비슷하지만, 두가지 중요한 차이점이 있습니다. 첫번째로, 함수가 실행될 때마다 새로운 범위 객체가 생성된다는 점과, 두번째로, (브라우저에서 window로 접근가능한) 전역 객체와 달리 범위 객체는 JavaScript 코드에서 직접적으로 액세스할 수 없다는 점입니다. 예를 들자면 현재 범위 객체의 속성에 반복 접근할 수 있는 수단이 없습니다.
따라서 makeAdder 가 불리워지면, 범위 객체는 makeAdder 함수에 매개변수로 넘겨진 하나의 속성 a를 가진 상태로 생성됩니다. 일반적으로 JavaScript의 가비지 컬렉터가 이때 makeAdder에 의해 생성된 범위 객체를 청소해야겠지만, 리턴된 함수가 여전히 범위 객체를 참조하고 있습니다. 결과적으로 범위 객체는 makeAdder에 의해 리턴된 함수 객체가 더는 참조되지 않을 때까지 가비지 컬렉터에 의해 정리되지 않게됩니다.
범위 객체는 JavaScript 객체 체계에서 사용되는 prototype 사슬과 비슷한 범위 사슬이라고 불리워지는 사슬을 형성합니다.
폐포는 함수와 함수에 의해 생성되는 범위 객체를 함께 지칭하는 용어입니다.
또한 폐포는 상태를 저장할 수 있도록 허용합니다 - 그렇기 때문에, 객체의 내부에서 자주 사용될 수 있는 것입니다.
메모리 누출
폐포의 부작용은 Internet Explorer에서 심각하지는 않지만 쉽게 메모리 누출이 된다는 것입니다. JavaScript는 가비지 컬렉트를 하는 언어 입니다. 객체가 생성됨에 따라서 메모리가 할당되고, 사용하고난 메모리는 더 참조하는 다른 객체가 없을 때 되돌아가는 방식으로 동작하는 언어란 말이죠. 호스트 환경에서 제공되는 객체들은 해당 환경에 의해 다뤄집니다.
브라우저 호스트는 HTML 페이지에 DOM 객체로서 표현되어있는 많은 수의 객체를 다뤄야 합니다. 이 객체들을 어떻게 할당하고 다시 거둬들일지는 브라우저 책임이죠.
Internet Explorer는 이를 위해 자신만의 고유한, JavaScript의 그것과는 다른 가비지 컬렉션 방식을 사용합니다. 두 언어간에 상호작용이 일어날 수 있고 이 과정에서 메모리 누출이 발생할 수 있습니다.
IE에서 메모리 누출은 JavaScript 객체와 고유 객체간에 참조하는 중 자기 자신을 참조 (circular reference, 순환 참조)하게 되는 일이 발생할 경우라면 언제든지 발생하게 됩니다. 다음을 고려해 보도록 합시다:
function leakMemory() {
var el = document.getElementById('el');
var o = { 'el': el };
el.o = o;
}
위의 코드는 순환 참조로서 메모리 누출을 일으킵니다. IE는 완전히 다시 시작되기 전까지는 el와 o에 의해 사용되는 메모리를 반환하지 못합니다.
위의 경우는 알아채지 못하고 지나갈 확률이 높습니다. 메모리 누출은 사실 오랫동안 실행되거나 큰 데이터 구조나 반복, 순환에 의해 누출된는 메모리 양이 많은 경우에서 실질적으로 고려할만한 가치가 생깁니다.
누출이 이처럼 명확한 경우는 드뭅니다. 누출을 일으키는 데이터 구조는 수차례에 걸친 참조 구조를 가지고 있어서 순환 참조를 하고있는지 명확하지 않은 경우가 더 많습니다.
폐포는 그렇게 되도록 하지않아도 간단하게 메모리 누출을 일으킬 수 있습니다. 다음을 고려해 봅시다:
function addHandler() {
var el = document.getElementById('el');
el.onclick = function() {
this.style.backgroundColor = 'red';
}
}
위의 코드는 클릭했을때 배경색이 빨강으로 바뀌는 엘레멘트를 설정합니다. 그리고 메모리 누출도 일으킵니다. 어째서냐고요? el을 참조하면 의도와는 달리 익명 내부 함수 때문에 생성된 폐포 내에 붙잡혀 있게 되기 때문입니다. 이는 JavaScript 객체 (내부 함수)와 원시 객체 (el)간에 순환 참조를 만듭니다.
이 문제를 피할 수 있는 많은 방법이 있습니다. 가장 간단한 건 이겁니다:
function addHandler() {
var el = document.getElementById('el');
el.onclick = function() {
this.style.backgroundColor = 'red';
}
el = null;
}
이렇게 하면 순환 참조 고리를 끊을 수 있습니다.
놀랍게도, 폐포에 의해 발생된 순환 참조를 고리를 끊기 위한 한 요령은 또다른 폐포를 추가하는 것입니다:
function addHandler() {
var clickHandler = function() {
this.style.backgroundColor = 'red';
}
(function() {
var el = document.getElementById('el');
el.onclick = clickHandler;
})();
}
내부 함수는 실행되고 바로 사라지므로서, clickHandler와 함께 생성된 폐포로부터 그 내용을 숨깁니다.
폐포를 피할 수 있는 또다른 좋은 요령은 window.onunload 이벤트가 발생하는 동안 순환 참조를 끊는 것입니다. 많은 이벤트 라이브러리가 이렇게 동작합니다. 주의할 것은 그렇게 하도록하면 Firefox 1.5의 bfcache를 비활성화 하게 되므로, 별 다른 이유가 없다면 Firefox에서 unload listener를 등록해서는 안 된다는 것입니다.

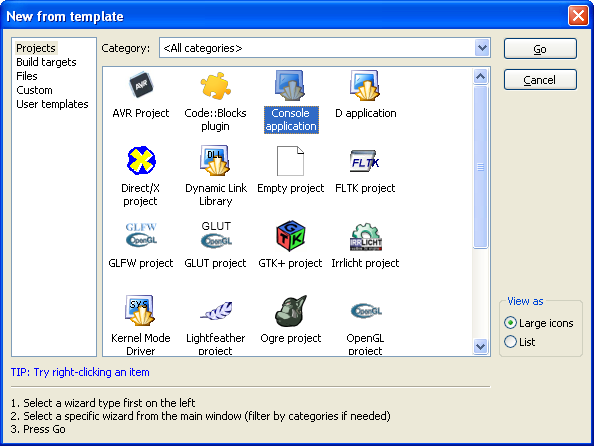
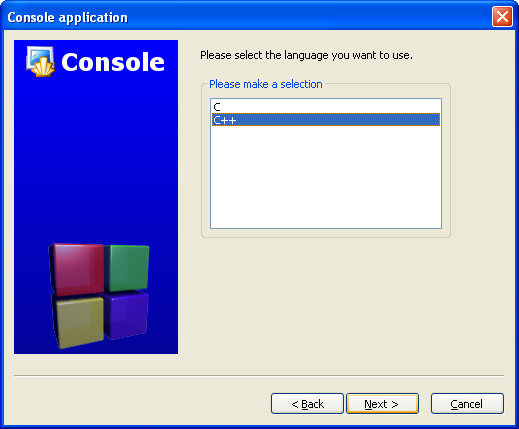
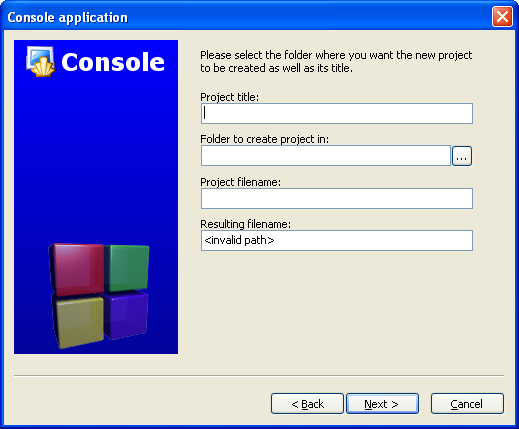
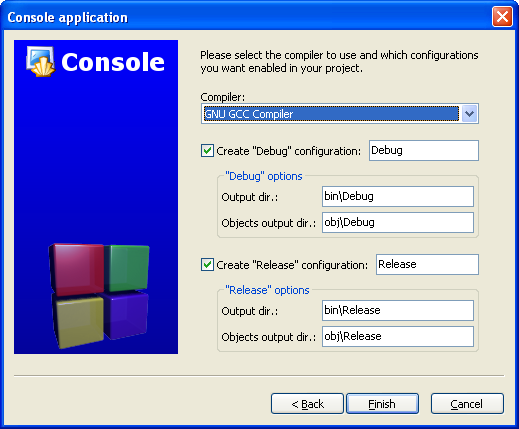
 (You may need to expand the contents of the "Sources" folder if you don't see main.cpp.)
(You may need to expand the contents of the "Sources" folder if you don't see main.cpp.) 


















 8mile .(8 Mile).DVDScreener.AC3_5.1ch-Tx.torrent
8mile .(8 Mile).DVDScreener.AC3_5.1ch-Tx.torrent
