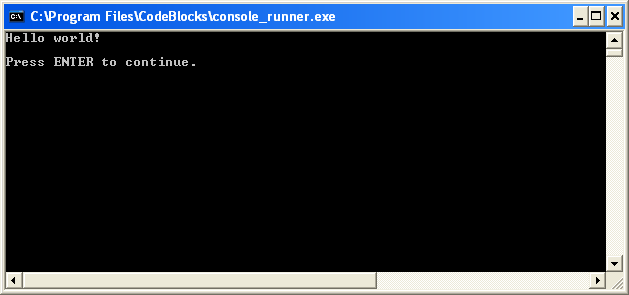
//
// Author : Al Dev Email: alavoor[AT]yahoo.com
// string class나 String class를 써라.
//
// 메모리 릭을 막기 위해 - 문자 변수를 관리하기 위한 문자 class
// char[]나 char *보다는 String class나 string class를 써라.
//
#ifndef __STRING_H_ALDEV_
#define __STRING_H_ALDEV_
// 프로그램이 커질 수록 iostream을 사용하지 말아라.
#ifdef NOT_MSWINDOWS
#include <iostream>
#else
#include <iostream.h> // 하위호환성을 위해. C++ 표준은 .h가 없다.
#endif // NOT_MSWINDOWS
#include <stdio.h> // File과 sprintf()를 위해
//#include <list.h> // list
// MS Windows 95 VC++과 Borland C++ 컴파일러인 경우 -
// d:\program files\CBuilder\include\examples\stdlib\list.cpp 와 include\list.h
// 을 보라.
//#include <list> // for list
//using namespace std;
const short INITIAL_SIZE = 50;
const short NUMBER_LENGTH = 300;
const int MAX_ISTREAM_SIZE = 2048;
//class StringBuffer;
// 나는 이 문자열 class를 Linux (Redhat 7.1)와 MS Windows Borland C++ v5.2 (win32)
// 에서 컴파일 / 테스트 해보았다.
// 또한, MS Visual C++ compiler에서도 작동할 것이다.
class String
{
public:
String();
String(const char bb[]); // + 연산자를 위해 필요
String(const char bb[], int start, int slength); // 문자들의 부분집합
String(int bb); // + 연산자를 위해 필요
String(unsigned long bb); // + 연산자를 위해 필요
String(long bb); // + 연산자를 위해 필요
String(float bb); // + 연산자를 위해 필요
String(double bb); // + 연산자를 위해 필요
String(const String & rhs); // + 연산자를 위해 필요한 copy constructor
//String(StringBuffer sb); // Java와의 호환성을 위해
// - 그러나 MS windows에서는
// 컴파일되지 않고, core dump를 일으킨다.
String(int bb, bool dummy); // StringBuffer class를 위해 필요
virtual ~String(); // virtual로 선언하여 상속받은 class의 소멸자가
// 불리도록 한다.
char *val() {return sval;} // sval을 public으로 하는 것은 위험하므로
// Java의 String을 흉내낸 함수들
unsigned long length();
char charAt(int where);
void getChars(int sourceStart, int sourceEnd,
char target[], int targetStart);
char* toCharArray();
char* getBytes();
bool equals(String str2); // == 연산자를 참조하라
bool equals(char *str2); // == 연산자를 참조하라
bool equalsIgnoreCase(String str2);
bool regionMatches(int startIndex, String str2,
int str2StartIndex, int numChars);
bool regionMatches(bool ignoreCase, int startIndex,
String str2, int str2StartIndex, int numChars);
String toUpperCase();
String toLowerCase();
bool startsWith(String str2);
bool startsWith(char *str2);
bool endsWith(String str2);
bool endsWith(char *str2);
int compareTo(String str2);
int compareTo(char *str2);
int compareToIgnoreCase(String str2);
int compareToIgnoreCase(char *str2);
int indexOf(char ch, int startIndex = 0);
int indexOf(char *str2, int startIndex = 0);
int indexOf(String str2, int startIndex = 0);
int lastIndexOf(char ch, int startIndex = 0);
int lastIndexOf(char *str2, int startIndex = 0);
int lastIndexOf(String str2, int startIndex = 0);
String substring(int startIndex, int endIndex = 0);
String replace(char original, char replacement);
String replace(char *original, char *replacement);
String trim(); // 오버로딩 된 trim을 참조하라.
String concat(String str2); // + 연산자를 참조
String concat(char *str2); // + 연산자를 참조
String concat(int bb);
String concat(unsigned long bb);
String concat(float bb);
String concat(double bb);
String reverse(); // 오버로딩 된 다른 reverse()를 참조
String deleteCharAt(int loc);
String deleteStr(int startIndex, int endIndex); // Java의 "delete()"
String valueOf(char ch)
{char aa[2]; aa[0]=ch; aa[1]=0; return String(aa);}
String valueOf(char chars[]){ return String(chars);}
String valueOf(char chars[], int startIndex, int numChars);
String valueOf(bool tf)
{if (tf) return String("true"); else return String("false");}
String valueOf(int num){ return String(num);}
String valueOf(long num){ return String(num);}
String valueOf(float num) {return String(num);}
String valueOf(double num) {return String(num);}
// 이 파일의 아래에 주어진 StringBuffer를 참고하라.
// ---- 여기까지 Java를 흉내낸 함수들 -----
//////////////////////////////////////////////////////
// Java에는 없는 추가적인 함수들
//////////////////////////////////////////////////////
String ltrim();
void ltrim(bool dummy); // 직접적으로 object를 변화시킨다.
String rtrim();
void rtrim(bool dummy); // 직접적으로 object를 변화시킨다.
// chopall 참고.
void chopall(char ch='\n'); // 맨 뒤의 ch를 없앤다. rtrim 참고.
void chop(); // 맨 뒤의 문자를 없앤다.
void roundf(float input_val, short precision);
void decompose_float(long *integral, long *fraction);
void roundd(double input_val, short precision);
void decompose_double(long *integral, long *fraction);
void explode(char *separator); // token()과 오버로딩 된 explode()참조
String *explode(int & strcount, char separator = ' '); // token()참조
void implode(char *glue);
void join(char *glue);
String repeat(char *input, unsigned int multiplier);
String tr(char *from, char *to); // character들을 바꾼다(translate).
String center(int padlength, char padchar = ' ');
String space(int number = 0, char padchar = ' ');
String xrange(char start, char end);
String compress(char *list = " ");
String left(int slength = 0, char padchar = ' ');
String right(int slength = 0, char padchar = ' ');
String overlay(char *newstr, int start = 0, int slength = 0, char padchar = ' ');
String at(char *regx); // regx의 첫번째 match
String before(char *regx); // regx 앞의 string
String after(char *regx); // regx 뒤의 string
String mid(int startIndex = 0, int length = 0);
bool isNull();
bool isInteger();
bool isInteger(int pos);
bool isNumeric();
bool isNumeric(int pos);
bool isEmpty(); // length() == 0 과 같은 상태
bool isUpperCase();
bool isUpperCase(int pos);
bool isLowerCase();
bool isLowerCase(int pos);
bool isWhiteSpace();
bool isWhiteSpace(int pos);
bool isBlackSpace();
bool isBlackSpace(int pos);
bool isAlpha();
bool isAlpha(int pos);
bool isAlphaNumeric();
bool isAlphaNumeric(int pos);
bool isPunct();
bool isPunct(int pos);
bool isPrintable();
bool isPrintable(int pos);
bool isHexDigit();
bool isHexDigit(int pos);
bool isCntrl();
bool isCntrl(int pos);
bool isGraph();
bool isGraph(int pos);
void clear();
int toInteger();
long parseLong();
double toDouble();
String token(char separator = ' '); // StringTokenizer와 explode()를 참조
String crypt(char *original, char *salt);
String getline(FILE *infp = stdin); // putline() 참조
//String getline(fstream *infp = stdin); // putline() 참조
void putline(FILE *outfp = stdout); // getline() 참조
//void putline(fstream *outfp = stdout); // getline() 참조
void swap(String aa, String bb); // aa를 bb로 바꾼다
String *sort(String aa[]); // String의 array를 sort한다
String sort(int startIndex = 0, int length = 0); // string 내의 character들을 sort
int freq(char ch); // ch가 들어있는 횟수를 센다
void Format(const char *fmt, ...);
String replace (int startIndex, int endIndex, String str);
void substring(int startIndex, int endIndex, bool dummy); // object를 직접 바꾼다
void reverse(bool dummy); // object를 직접 바꾼다
String deleteCharAt(int loc, bool dummy); // object를 직접 바꾼다
String deleteStr(int startIndex, int endIndex, bool dummy);
void trim(bool dummy); // object를 직접 바꾼다
String insert(int index, String str2);
String insert(int index, String str2, bool dummy); // object를 직접 바꾼다
String insert(int index, char ch);
String insert(int index, char ch, bool dummy); // object를 직접 바꾼다
String insert(char *newstr, int start = 0, int length = 0, char padchar = ' ');
String dump(); // od -c 와 같이 string을 dump한다.
// Java의 StringBuffer를 위해 필요한 것들
void ensureCapacity(int capacity);
void setLength(int len);
void setCharAt(int where, char ch); // charAt(), getCharAt() 참고
// Java의 Integer class, Long, Double class를 위해 필요
int parseInt(String ss) {return ss.toInteger();}
int parseInt(char *ss)
{String tmpstr(ss); return tmpstr.toInteger();}
long parseLong(String ss) {return ss.parseLong();}
long parseLong(char *ss)
{String tmpstr(ss); return tmpstr.parseLong();}
float floatValue() {return (float) toDouble(); }
double doubleValue() {return toDouble(); }
char * number2string(int bb); // String(int) 참고
char * number2string(long bb); // String(long) 참고
char * number2string(unsigned long bb); // String(long) 참고
char * number2string(double bb); // String(double) 참고
///////////////////////////////////////////////
// 겹치는 함수 이름들
///////////////////////////////////////////////
// char * c_str() // val() 을 대신사용
// bool find(); // regionMatches() 를 대신사용
// bool search(); // regionMatches() 를 대신사용
// bool matches(); // regionMatches() 를 대신사용
// int rindex(String str2, int startIndex = 0); lastIndexOf() 을 대신사용
// String blanks(int slength); // repeat() 를 대신사용
// String append(String str2); // concat() 이나 + operator 을 대신사용
// String prepend(String str2); // + operator을 대신사용 append()참고
// String split(char separator = ' '); // token(), explode() 나 StringTokenizer class 를 대신사용
bool contains(char *str2, int startIndex = 0); // indexOf() 를 대신사용
// void empty(); is_empty() 를 대신사용
// void vacuum(); clear() 를 대신사용
// void erase(); clear() 를 대신사용
// void zero(); clear() 를 대신사용
// bool is_float(); is_numeric(); 을 대신사용
// bool is_decimal(); is_numeric(); 을 대신사용
// bool is_Digit(); is_numeric(); 을 대신사용
// float float_value(); toDouble(); 을 대신사용
// float tofloat(); toDouble(); 을 대신사용
// double double_value(); toDouble(); 을 대신사용
// double numeric_value(); toDouble(); 을 대신사용
// int int_value(); toInteger() 를 대신사용
// int tonumber(); toInteger() 를 대신사용
// String get(); substring() 이나 val() 을 대신 사용. 그러나 Java 스타일의 substring이 더 좋다
// String getFrom(); substring() 이나 val() 을 대신 사용. 그러나 Java 스타일의 substring이 더 좋다
// String head(int len); substring(0, len) 을 대신사용
// String tail(int len); substring(length()-len, length()) 를 대신사용
// String cut(); deleteCharAt() 이나 deleteStr() 을 대신사용
// String cutFrom(); deleteCharAt() 이나 deleteStr() 을 대신사용
// String paste(); insert() 를 대신사용
// String fill(); replace() 를 대신사용
// char firstChar(); // substring(0, 1); 을 대신사용
// char lastChar(); // substring(length()-1, length()); 를 대신사용
// String findNext(); token(), explode() 이나 StringTokenizer class 를 대신사용
// begin(); iterator. operator [ii]를 대신사용
// end(); iterator. operator [ii]를 대신사용
// copy(); assignment = 연산다를 대신 사용, String aa = bb;
// clone(); assignment = 연산자를 대신 사용, String aa = bb;
// void putCharAt(int where, char ch); setCharAt() 을 대신사용
// void replaceCharAt(int where, char ch); setCharAt() 을 대신사용
// char getCharAt(int where); CharAt() 을 대신사용
// void parseArgs(int where, char ch); StringTokensizer class, token() 이나 explode() 를 대신사용
// void truncate(); trim(), rtrim(), chop() 이나 chopall() 을 대신사용
// 숫자를 string으로 변환 : notostring(), int2str, long2str은 number2string()을 사용
// 연산자들...
String operator+ (const String & rhs);
friend String operator+ (const String & lhs, const String & rhs);
String& operator+= (const String & rhs); // 레퍼런스를 이용하면 더 빠를 것이다.
String& operator= (const String & rhs); // 레퍼런스를 이용하면 더 빠를 것이다.
bool operator== (const String & rhs); // 레퍼런스를 이용하면 더 빠를 것이다.
bool operator== (const char *rhs);
bool operator!= (const String & rhs);
bool operator!= (const char *rhs);
char operator [] (unsigned long Index) const;
char& operator [] (unsigned long Index);
friend ostream & operator<< (ostream & Out, const String & str2);
friend istream & operator>> (istream & In, String & str2);
bool String::operator< (const char *rhs) const; // map & vector 를 위한 유용한 method
bool String::operator< (const String & rhs) const; // map & vector 를 위한 유용한 method
//do later: static list<String> explodeH; // list head
protected:
char *sval; // sval을 public으로 하는 것은 위험하다.
void verifyIndex(unsigned long index) const; // Win32에서의 warning때문에 inline이 아니다.
void verifyIndex(unsigned long index, char *aa) const;// Win32에서의 warning때문에 inline이 아니다.
void _str_cat(char bb[]);
void _str_cat(int bb);
void _str_cat(unsigned long bb);
void _str_cat(float bb);
void _str_cpy(char bb[]);
void _str_cpy(int bb); // itoa
void _str_cpy(unsigned long bb);
void _str_cpy(float bb); // itof
private:
// Note: 모든 private 변수와 함수는 _ (밑줄)로 시작한다.
//static String *_global_String; // add 연산에서 필요
//inline void _free_glob(String **aa);
bool _equalto(const String & rhs, bool type = false);
bool _equalto(const char *rhs, bool type = false);
String *_pString; // 내부에서 사용하는 임시 포인터
char *_pNumber2String; // 내부에서 사용하는 임시 포인터
inline void _allocpString();
inline void _allocpNumber2String();
inline void Common2AllCstrs();
inline void _reverse();
inline void _deleteCharAt(int loc);
inline void _deleteStr(int startIndex, int endIndex);
inline void _trim();
inline void _ltrim();
inline void _rtrim();
inline void _substring(int startIndex, int endIndex);
void _roundno(double input_dbl, float input_flt, short precision, bool type);
};
// 전역변수는 String.cpp 에서 정의된다
#endif // __STRING_H_ALDEV_ |

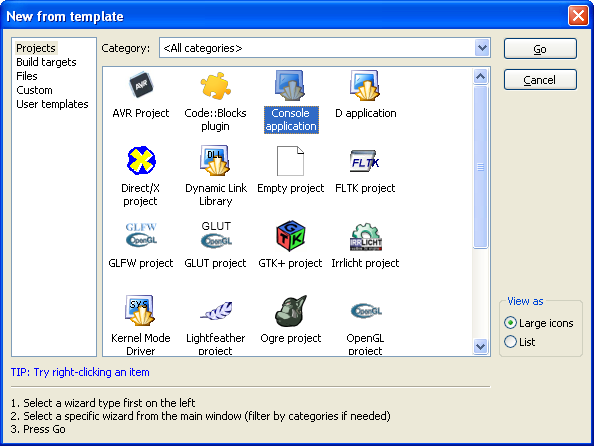
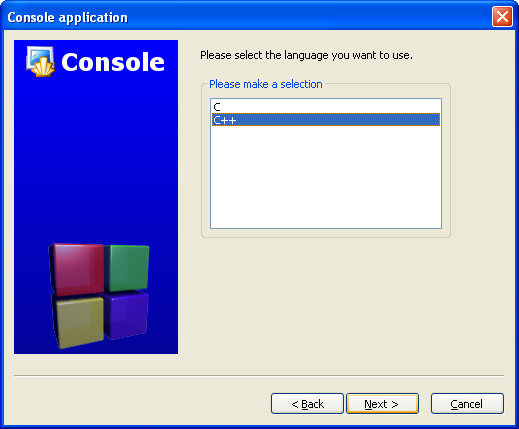
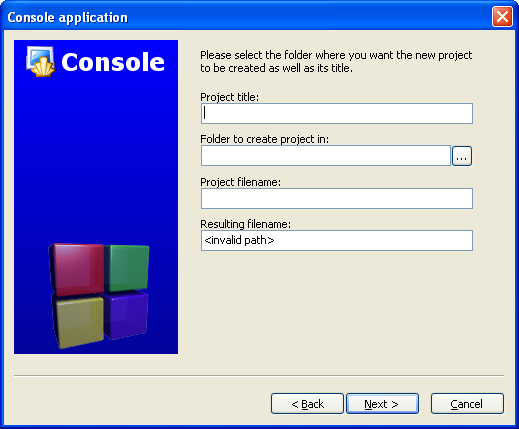
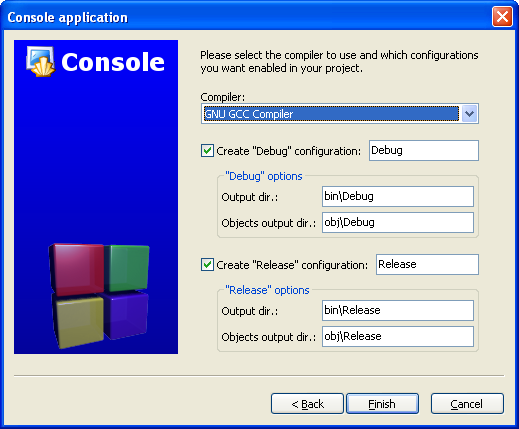
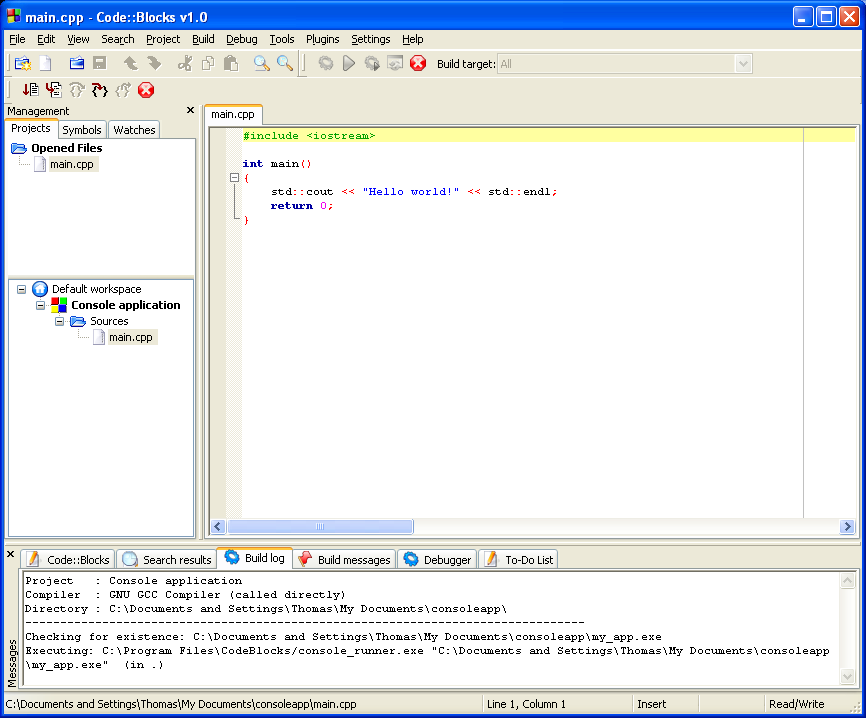 (You may need to expand the contents of the "Sources" folder if you don't see main.cpp.)
(You may need to expand the contents of the "Sources" folder if you don't see main.cpp.)